


As an industry, we need to start viewing information as an important asset in its own right, on par with the physical built facility. And all this starts with the asset owners, the clients. Clients procure buildings, bridges, and roads, but they also procure the information that relates to them which is just as important. If that information is received in a way that is useful and there are processes in place to manage it, it can provide great value to organisations. This is what helps built assets stay safe and allow sound business decisions to be made.
But to do this, information management needs to be given more attention and resources within organisations than it currently does. It should be defined before any projects and other appointments take place by managing the information exchanges that happen within organisations, this helps to determine why built asset information is needed. Clients are the most important actors in information management as they provide the inputs and set up the framework.
What is information management?
Information management provides a framework to support the specification, delivery, and governance of all information (unstructured and structured) across a built asset’s life.
Information management is about the specification, delivery, and governance of just the right amount of information concerning the design, construction, operation, maintenance, and decommissioning of buildings and infrastructure and that’s across all information (whether that’s structured in databases or unstructured in drawings and documents). This ultimately allows us to track and receive trusted information that is useful.
Building information modelling (BIM) is concerned with the management of structured information within the wider information management framework. Its key aim is to make as much of our information as structured as possible utilising information models to connect it all up. Only when it is structured, can we find, share, assure and query information through automation and at a bigger scale to ultimately gain insight.
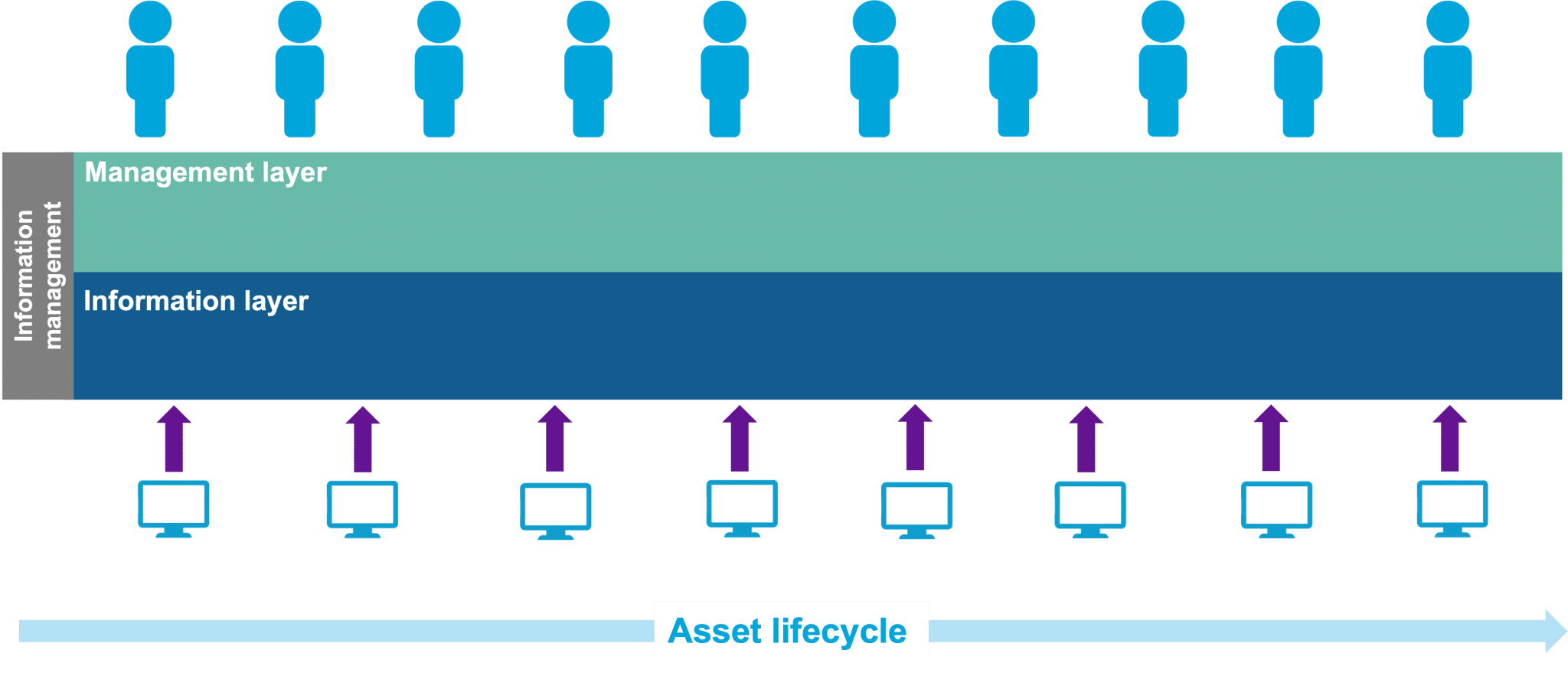
To describe information management visually, across an asset’s life, there is both an activity-based management layer, which people interact with, and an information layer, which technology mainly interacts with. It’s both these layers that make up information management.
In reality, we are sadly still working in a tangled and highly chaotic web of stuff. Incorrect, incomplete, and lost information introduces so much risk to projects and organisations, yet for an industry obsessed with risk, it’s barely ever thought about. As we create more data, develop new standards, processes, and technology, and form new initiatives, this beast is growing and getting more tangled by the day.
Over the years in the built and natural environment, there has been an increase in the need for information, from best practices, standards, policies, and regulations—a great example is what is now required for the Building Safety Act. This has resulted in more and more information (and data) being produced.
Technology allows us to produce vast amounts of information quite easily and readily, but the main problem lies in its quality, which is compromised by a lack of trust and constant overlapping, contradicting, and duplication. And while technology has evolved substantially, our maturity concerning information has not, so we are guided by technology and not by the information itself and the science behind it.
If we think of the industry as a tree — the top part being the information and data which is growing rapidly, chaotically and getting bigger by the day — in comparison to the small roots which represent what we have in terms of the understanding and implementation of information science principles. A tree with weak roots will not only impair the growth above, but it will also become unstable.
The worry is, it will become too chaotic that we can’t unpick it. There’s a growing focus on technological solutions that incorporate artificial intelligence (AI). But while it’s important to see where AI fits into the overall information management puzzle, it will not automatically solve the industry’s greatest challenges. We’ve seen time and time again that when uncontrolled and unsupervised, applying technology on its own, doesn’t work. The danger is that AI could move us even further away from understanding our information, raising the same questions about quality and trust.
We need to do the groundwork to make the roots bigger and to set out the basic principles and how it all joins up, to work towards a universal bigger picture. But there are barriers in the way.
Barriers to better information management
Information barriers can disrupt information flows within an organisation, leading to inefficiencies and information waste. These challenges are often rooted in organisational structures, people-oriented factors, and technology-related issues.
Organisational challenges primarily stem from departmental silos or hierarchical structures that impair communication and collaboration. For example, the separation of capital projects and operations can silo the management of capital projects and the ongoing operational activities of an organisation making it difficult to have one set of agreed information requirements.
One of the greatest barriers comes down to procurement models and insurance that dictate adversarial behaviours this impacts significantly on the type of information that is produced and how it flows between parties.
Addressing people-oriented factors involves addressing the basics of information and data literacy but also attracting people with advanced information and data science skills and knowledge. It’s also about understanding the need for ongoing change management to help people understand the ‘why’ using different forms of communication.
In terms of technology, ever since CAD software was introduced, its language, structure, and rules have been crucial in defining information for the asset, which is often poorly considered. With the advancement of BIM, this technology first approach has only gotten worse. Software applications are tools that process information they should never be used to define it. The structure and language of information should be defined outside of software considering the bigger information management picture and be neutral and open.
Therefore, information should be defined independently of software applications. Technology is important, of course. However, it needs to serve the information not the other way round.
The management layer of information management
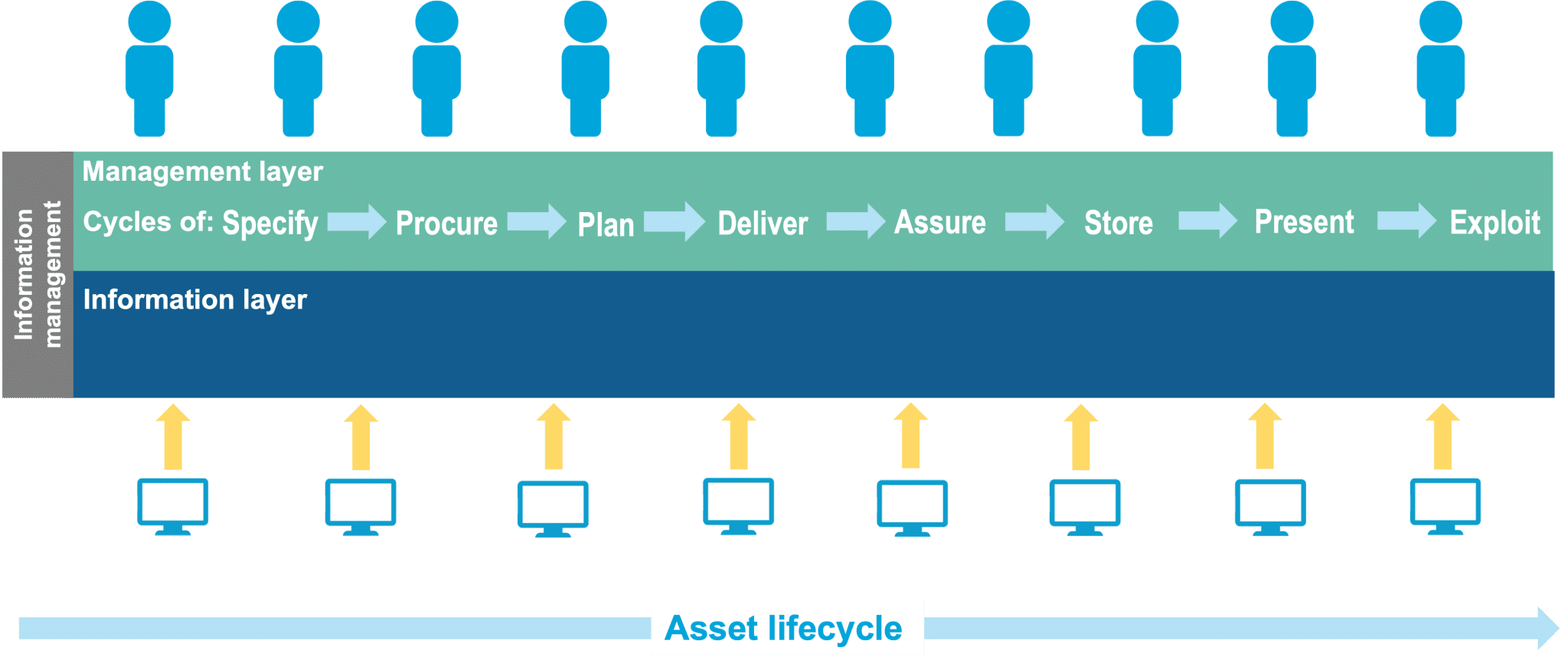
The management layer consists of cycles of activities required to manage information, these are similar to the activities that the Government and Industry Interoperability Group (GIIG) is based upon. It is important to understand that the activities are appointment based not work-stage-based, therefore each appointment has its own information timeline. Therefore, after the need and requirements have been established within an organisation for each appointment the information receiver (for example, a client) specifies what information is needed and uses this to select the right suppliers to deliver the information (this goes into contracts). Next, the suppliers plan the delivery and deliver the information where it is assured against the original requirements and hosted within a store. The information is then presented or visualised for reporting purposes and used or exploited to manage projects (and other trigger events), assets or an entire organisation.
These activities represent what ISO 19650 is all about and why ISO 19650 is the standard to govern the management layer. Going through each activity would create a very long paper therefore the below concentrates on the specification and plan activities.
ISO 19650 and focusing on the specification and plan activities
In ISO 19650 more responsibility is put onto the client to set up the information management ecosystem before any projects are started. This starts with clients defining their information requirements. However, in the past we have seen that some clients will ask for everything in the standards, others will ask the delivery team to tell them what they want, or others will just ask for BIM. Therefore, more focus has been put on the purposes of information, whether that’s to perform a task, answer a question, or make a decision, to effectively manage events such as projects or maintenance activities, but also the assets or even an organisation. This is what determines the content of information requirements.
Information requirements are made up of both unstructured and structured information generated as the result of defining purposes. Structured information is object-based so we need to specify the information against the objects. From here we can use the level of information-need framework which helps to break information down both: alphanumerically and geometrically and enables objects to be related to documentation. Metadata also needs defining and for unstructured information, the content can be specified. This all needs to be considered in the context of when is it required and which appointment will deliver it, ultimately creating a filtered set called ‘exchange information requirements’. The Information Delivery Specification (IDS) which you might have heard of (developed by buildingSMART International) provides a machine-interpretable language to ensure the delivered information meets these requirements.
When specifying information requirements the three below guidelines should be considered:
- Information requirements should be defined at a portfolio level and filtered and adapted to create exchange information requirements.
- Information requirements should be created within a database as they are formed of multiple connected facets.
- Exchange information requirements are for the purpose of tendering and providing the base of the master information delivery plan.
When we think of information requirements we always think of the appointing party or the client, but actually everyone has information requirements. ISO 19650 doesn’t currently cover everyone, but it does cover the lead appointed party’s information requirements. This isn’t well understood. So, if you’re directly appointed to the client for example a designer, employer’s agent, cost consultant or main contractor you take the client’s information requirements and incorporate them within your own, to assess the capability and capacity of any suppliers you have.
After the appointment of the client’s supplier, the combined information requirements are then detailed further to make them practically deliverable. The first step is listing the actual deliverables. This is done by taking the information requirements and using them as the base data set to create the master information delivery plan. In other words, it’s a programme for delivering information. At this point, the object breakdown is more granular for work packages and the aspect of time is more complex as it links to actual tasks.
The information layer of information management
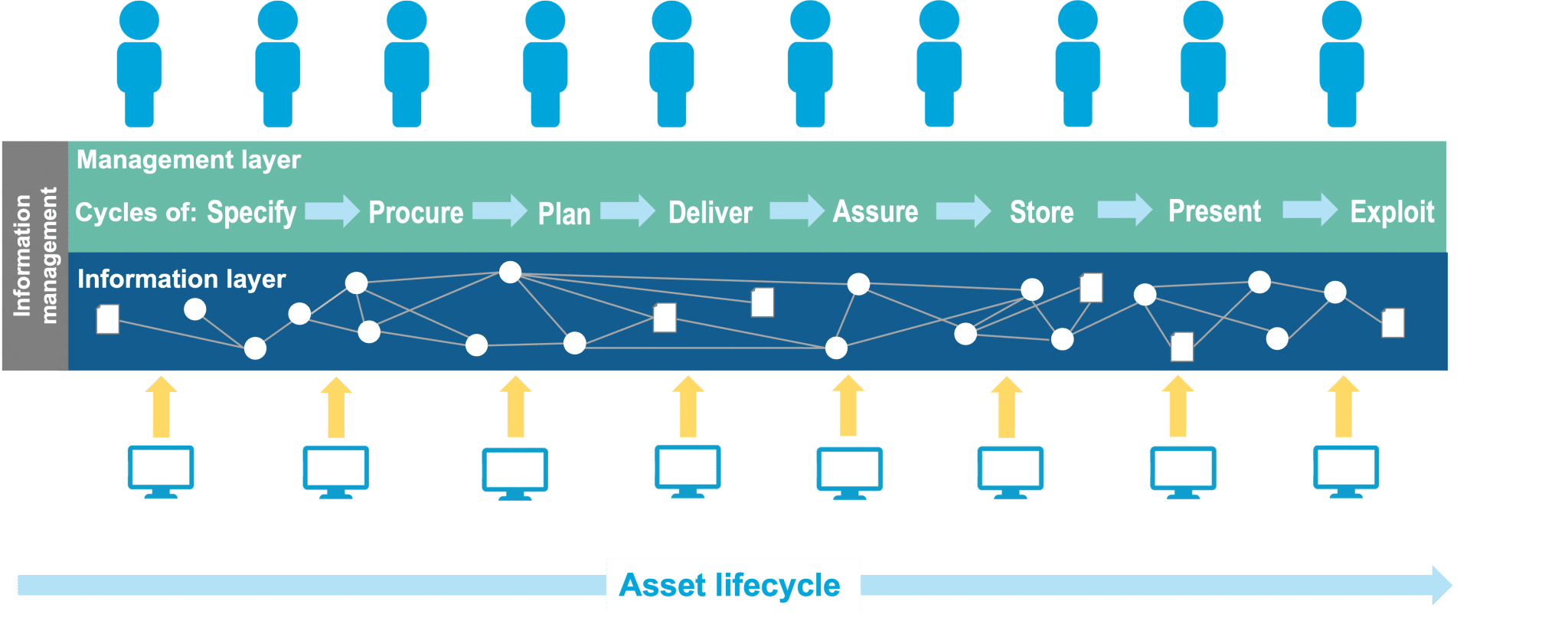
Across all the activities in the management layer, the information needs to be named, ordered, and connected in the same consistent way. This is the job of the information layer.
The information layer is concerned with the organisation and constraints of information to enable information to be connected and shared, this layer can also be thought of as data.
Within this layer, there are many standards, and it is important to understand why standardisation is required.
Returning to the point about the technology first approach, over the years, since the introduction of CAD software, we’ve observed that the proprietary language, structure, and rules of software have played a significant role in defining information for assets, rather than considering the needs of the organisation. While this approach works within the specific software environment, it becomes problematic when you try to use it elsewhere. Information created for one software environment often struggles to exist outside of it or can’t be easily shared because it’s in a different language that’s incompatible with other systems. This can create a point-to-point scenario where data must be transformed and translated as it is passed on between applications. As the number of applications we use grows, we will have hundreds of potential permutations.
But that’s only the start, if we drill down further… as asset owners adopt more data-based ways of working we have the scenario where each user will have their own bespoke data structure (even though they will be very similar) and this creates a limitless number of permutations and is an interoperability time bomb waiting to explode!
There needs to be a longer-term sustainable solution to this exchange problem.
Currently, even at one simple exchange, we can have problems getting the right data out of one system to then into another. As an industry, we have huge problems with interoperability and as a result, we struggle to get our systems to work together, this isn’t just in the design stages but throughout a facility’s life.
So, what is the answer?
- We put information first so it’s the software which serves the information, not the other way around.
- We open up information so we are not limiting which software applications can plug in.
- We use a standard approach, so the data doesn’t require so much transforming.
So rather than this point-to-point scenario we get a baseline information layer which spans an asset’s life containing all the standardised structures, rules, and language to enable information to be shared.
If we have standardisation, this enables the receiving platform to know where to look for the data it needs and what the relationships are, so it too can make sense of it. This allows us to automate tasks, such as checking, analysing large data sets, and carrying out predictions.
Several standards occupy this layer. However, to give us any chance of joining this up we need to use an object-based approach because it’s the objects that connect everything, an approach that utilises schemas and data models. One such data model and schema that provides the foundational object framework to represent the built environment is Industry Foundation Classes (IFC).
What is the Industry Foundation Classes (IFC) format?
Industry Foundation Classes or IFC, provides the object structure and connections in the information layer. This is managed by buildingSMART International a non-profit organisation. In basic terms, it sets out how objects or ‘things’ are ordered and how they relate to each other. Humans see buildings and infrastructure as physical things; we know that windows are in walls and columns connect to beams. A computer however needs to be able to understand the same things via a computer language and that’s what IFC is, it’s a digital representation of a facility.
At its core is an object-based data model, which provides the rules to give everything a unique place and to connect it all up. It contains three important parts: entities, attributes, and relationships. These entities can cover anything, including a door, a system, a whole facility, a task, and some even represent geometry. And there are some entities which allow us to connect to the outside world. We can link documentation to objects (therefore very importantly connecting structured and unstructured information), link to external databases which will contain their own data models and dictionaries for product manufacturers’ data and add classifications to give it a local language.
Looking at classification further, IFC for its objects uses a neutral language because it has to span all sectors, and all purposes and, because it’s international, all countries. It’s also for computers; therefore, the language is very logical — language that most of us in the built environment don’t use. For example, ‘IfcLightFixture.PointSource’ is a light which emits from a point, but you wouldn’t go down to your local B&Q store and ask where the point source lights are. So, we need to be able to attach a language to these IFC objects to customise them to the needs of a sector, purpose, or country. This is where classification comes in. Uniclass provides the UK-based language, it tags an IFC object bridging the gap between humans and the IFC data model. But IFC is not the same as a classification system, IFC allows for an effective data exchange.
IFC is a framework of connections or a model of data and it’s the connections or the relationships which make it so powerful. It connects objects such as the pump to other objects and those objects contain their own metadata. This enables the pump to be associated to a space and a building and a site just from tracking through the relationships. This relationship is not required to be stored as a string in the pump name.
We need to start thinking of relationships as being just as important if not more so as the entities or objects. In the image below, it’s the arrows that are the most important part of the model.
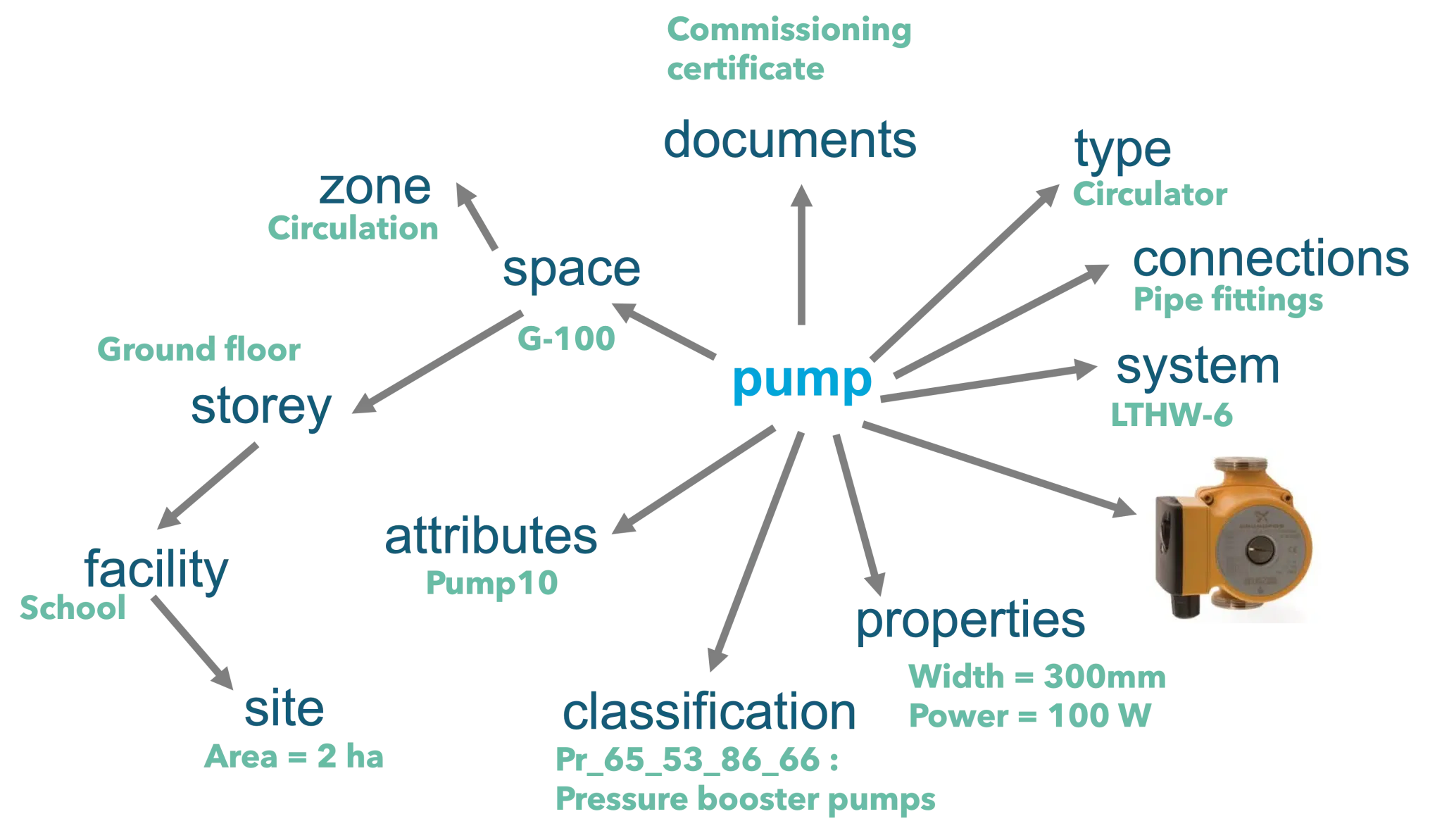
If we’re doing it right, IFC should be hidden in the background minding its own business and doing its job connecting data throughout an asset’s life. Most people should only see how the data is visualised or presented as information.
This can be in the form of dashboards, tables, data sheets, 3D models even construction drawings and text documents. The important part is to structure the data in accordance with the IFC schema and it can be used and displayed in so many ways.
It’s also important to understand the IFC data model doesn’t have to contain any geometrical data, the objects can just be connected to properties and visualised as a table if needed.
To transport the data, we need exchange formats. Because we are still file-based, the main format we exchange is the STEP physical format which is text-based and because it confusingly has the .ifc file extension, this has caused a big misunderstanding with many thinking IFC is just a file format and not an entire data model and schema. XML is also commonly used while another three are in development for linked data. When you think of IFC, it’s important to think of it as a data model, not a file format.
Bringing the management and information layers of information management together
It’s really important to understand that for effective information management, both layers have to be considered together. When we do this, it becomes clear that all the activities in the management layer are to enable the planning, creation, updating, and maintenance of connected information across the life of an asset, using standardised schemas and data models like IFC. This isn’t just about design and construction but the entirety of the information management cycle.
This connected information is described in ISO 19650 as an ‘information model’. But this is where we always go wrong and where we need to start to change people’s perceptions. Because at the moment what we deliver isn’t connected, it’s a dump of separate drawings, documents, spreadsheets, 3D models and data, that don’t relate to each other, and the majority of the information is trapped in files.
What do we mean by information models?
A truly connected information (or data) model of entities and relationships connects data, geometry, and documentation within a database. So, when you select something, you know who created it and when and what it is connected to. This is very similar to what IFC can do. A data model such as IFC has the potential to provide this base structure of an information model within a CDE, connecting alphanumerical, geometrical information and documentation, therefore IFC is much more than a file exchange between Revit and Tekla for example.
It’s important to understand that industry-wide standardised data models used within the industry have to be open (not proprietary), not controlled by profit-making organisations and they have to be held accountable the best way is to be governed by international standards.
So rather than having CDEs as they currently are, as document management systems, we should start to release the trapped data from files and put it directly in the CDE database. It’s here that we can connect it with any remaining documentation, so we can find, share, and query, not using files, but discrete data. The word information ‘container’ was purposely used in ISO 19650 rather than ‘file’ to set us up for this.
The project information model and asset information model become truly connected data models working in the background of a database, that grow and change as those delivering information are feeding into it. For those managing projects or assets tapping into this rich connected data means that reporting becomes easier and more in depth.
For example, we could ask a database to tell us how many boilers are in building X and what spaces they are all in. To do this the database will look for building X and then through the relationships find the boilers and then the associated spaces and perform a count of the boilers. It could also tell us the information associated to the boilers and this could be scaled up across an entire estate.
ISO 19650 is very much about the management of information models, specifying the contents, procuring, planning, delivering and assuring it so that the information can be trusted and that they are kept in sync with the real-world physical asset.
Conclusion
Rethinking information management and modelling provides the foundations for everything digital, the golden thread, digital twins and of course AI. All this will help large language models learn in a controlled accelerated way using good data, not the chaos we have now — which will just give us rubbish in and rubbish out. We need accurate information which can be trusted, ultimately peoples’ safety relies upon it.
You might be thinking we’ll never do all this; we can’t even do coordinates! If we want to retain control over our information, we don’t have a choice. We ultimately have a decision to make about which path we go down. We either realise we are an industry which is completely fuelled by information and data, which affects everyone, and we invest properly and work together as one unit to make what we have work and lay the foundations together. Or information chaos will overwhelm us.
To get started with better information management, book a demo to speak to an expert.